Question Generation
![]()
This is a bare bones tutorial showing what is possible with the QuestionGenerator Nodes and Pipelines which automatically generate questions which the question generation model thinks can be answered by a given document.
Prepare environment
Colab: Enable the GPU runtime
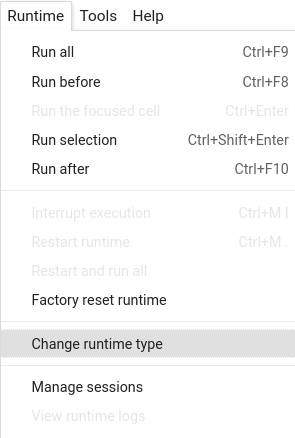
Make sure you enable the GPU runtime to experience decent speed in this tutorial.
Runtime -> Change Runtime type -> Hardware accelerator -> GPU
# Install the latest release of Haystack in your own environment
#! pip install farm-haystack
# Install the latest master of Haystack
!pip install --upgrade pip
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]
Logging
We configure how logging messages should be displayed and which log level should be used before importing Haystack. Example log message: INFO - haystack.utils.preprocessing - Converting data/tutorial1/218_Olenna_Tyrell.txt Default log level in basicConfig is WARNING so the explicit parameter is not necessary but can be changed easily:
import logging
logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
logging.getLogger("haystack").setLevel(logging.INFO)
# Imports needed to run this notebook
from pprint import pprint
from tqdm import tqdm
from haystack.nodes import QuestionGenerator, BM25Retriever, FARMReader
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.pipelines import (
QuestionGenerationPipeline,
RetrieverQuestionGenerationPipeline,
QuestionAnswerGenerationPipeline,
)
from haystack.utils import launch_es, print_questions
Let's start an Elasticsearch instance with one of the options below:
# Option 1: Start Elasticsearch service via Docker
launch_es()
# Option 2: In Colab / No Docker environments: Start Elasticsearch from source
! wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q
! tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
! chown -R daemon:daemon elasticsearch-7.9.2
import os
from subprocess import Popen, PIPE, STDOUT
es_server = Popen(
["elasticsearch-7.9.2/bin/elasticsearch"], stdout=PIPE, stderr=STDOUT, preexec_fn=lambda: os.setuid(1) # as daemon
)
# wait until ES has started
! sleep 30
Let's initialize some core components
text1 = "Python is an interpreted, high-level, general-purpose programming language. Created by Guido van Rossum and first released in 1991, Python's design philosophy emphasizes code readability with its notable use of significant whitespace."
text2 = "Princess Arya Stark is the third child and second daughter of Lord Eddard Stark and his wife, Lady Catelyn Stark. She is the sister of the incumbent Westerosi monarchs, Sansa, Queen in the North, and Brandon, King of the Andals and the First Men. After narrowly escaping the persecution of House Stark by House Lannister, Arya is trained as a Faceless Man at the House of Black and White in Braavos, using her abilities to avenge her family. Upon her return to Westeros, she exacts retribution for the Red Wedding by exterminating the Frey male line."
text3 = "Dry Cleaning are an English post-punk band who formed in South London in 2018.[3] The band is composed of vocalist Florence Shaw, guitarist Tom Dowse, bassist Lewis Maynard and drummer Nick Buxton. They are noted for their use of spoken word primarily in lieu of sung vocals, as well as their unconventional lyrics. Their musical stylings have been compared to Wire, Magazine and Joy Division.[4] The band released their debut single, 'Magic of Meghan' in 2019. Shaw wrote the song after going through a break-up and moving out of her former partner's apartment the same day that Meghan Markle and Prince Harry announced they were engaged.[5] This was followed by the release of two EPs that year: Sweet Princess in August and Boundary Road Snacks and Drinks in October. The band were included as part of the NME 100 of 2020,[6] as well as DIY magazine's Class of 2020.[7] The band signed to 4AD in late 2020 and shared a new single, 'Scratchcard Lanyard'.[8] In February 2021, the band shared details of their debut studio album, New Long Leg. They also shared the single 'Strong Feelings'.[9] The album, which was produced by John Parish, was released on 2 April 2021.[10]"
docs = [{"content": text1}, {"content": text2}, {"content": text3}]
# Initialize document store and write in the documents
document_store = ElasticsearchDocumentStore()
document_store.write_documents(docs)
# Initialize Question Generator
question_generator = QuestionGenerator()
Question Generation Pipeline
The most basic version of a question generator pipeline takes a document as input and outputs generated questions which the the document can answer.
question_generation_pipeline = QuestionGenerationPipeline(question_generator)
for idx, document in enumerate(document_store):
print(f"\n * Generating questions for document {idx}: {document.content[:100]}...\n")
result = question_generation_pipeline.run(documents=[document])
print_questions(result)
Retriever Question Generation Pipeline
This pipeline takes a query as input. It retrieves relevant documents and then generates questions based on these.
retriever = BM25Retriever(document_store=document_store)
rqg_pipeline = RetrieverQuestionGenerationPipeline(retriever, question_generator)
print(f"\n * Generating questions for documents matching the query 'Arya Stark'\n")
result = rqg_pipeline.run(query="Arya Stark")
print_questions(result)
Question Answer Generation Pipeline
This pipeline takes a document as input, generates questions on it, and attempts to answer these questions using a Reader model
reader = FARMReader("deepset/roberta-base-squad2")
qag_pipeline = QuestionAnswerGenerationPipeline(question_generator, reader)
for idx, document in enumerate(tqdm(document_store)):
print(f"\n * Generating questions and answers for document {idx}: {document.content[:100]}...\n")
result = qag_pipeline.run(documents=[document])
print_questions(result)
Translated Question Answer Generation Pipeline
Trained models for Question Answer Generation are not available in many languages other than English. Haystack provides a workaround for that issue by machine-translating a pipeline's inputs and outputs with the TranslationWrapperPipeline. The following example generates German questions and answers on a German text document - by using an English model for Question Answer Generation.
# Fill the document store with a German document.
text1 = "Python ist eine interpretierte Hochsprachenprogrammiersprache für allgemeine Zwecke. Sie wurde von Guido van Rossum entwickelt und 1991 erstmals veröffentlicht. Die Design-Philosophie von Python legt den Schwerpunkt auf die Lesbarkeit des Codes und die Verwendung von viel Leerraum (Whitespace)."
docs = [{"content": text1}]
document_store.delete_documents()
document_store.write_documents(docs)
# Load machine translation models
from haystack.nodes import TransformersTranslator
in_translator = TransformersTranslator(model_name_or_path="Helsinki-NLP/opus-mt-de-en")
out_translator = TransformersTranslator(model_name_or_path="Helsinki-NLP/opus-mt-en-de")
# Wrap the previously defined QuestionAnswerGenerationPipeline
from haystack.pipelines import TranslationWrapperPipeline
pipeline_with_translation = TranslationWrapperPipeline(
input_translator=in_translator, output_translator=out_translator, pipeline=qag_pipeline
)
for idx, document in enumerate(tqdm(document_store)):
print(f"\n * Generating questions and answers for document {idx}: {document.content[:100]}...\n")
result = pipeline_with_translation.run(documents=[document])
print_questions(result)
About us
This Haystack notebook was made with love by deepset in Berlin, Germany
We bring NLP to the industry via open source! Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
Get in touch: Twitter | LinkedIn | Slack | GitHub Discussions | Website
By the way: we're hiring!