Haystack
Get Started : If you'd already like to start installing Haystack and building your first system, please check out Get Started.
Overview
Haystack is an open-source framework for building search systems that work intelligently over large document collections. Recent advances in NLP have enabled the application of question answering, retrieval and summarization to real world settings and Haystack is designed to be the bridge between research and industry.
NLP for Search: Pick components that perform retrieval, question answering, reranking and much more
Latest models: Utilize all transformer based models (BERT, RoBERTa, MiniLM, DPR) and smoothly switch when new ones get published
Flexible databases: Load data into and query from a range of databases such as Elasticsearch, Milvus, FAISS, SQL and more
Scalability: Scale your system to handle millions of documents and deploy them via REST API
Domain adaptation: All tooling you need to annotate examples, collect user-feedback, evaluate components and finetune models.
Enabling New Styles of Search
Haystack is designed to take your search to the next level. Keyword search is effective and appropriate for many situations, but Machine Learning has enabled systems to search based on word meaning rather than string matching. As new language processing models are developed, new styles of search are also possible. In Haystack, you can create systems that perform:
This is just a small subset of the kinds of systems that can be created in Haystack.
The 3 Levels of Haystack
Haystack is geared towards building great search pipelines that are customizable and production ready. There are many different levels on which you can interact with the components in Haystack.
1) Nodes
Haystack offers different Nodes that perform different kinds of text processing. These are often powered by the latest transformer models and code-wise they are Python classes whose methods can be called directly. For example, if you would like to perform question answering with a Reader model, all you need to do is provide it with documents and a question.
Working on this level with Haystack Nodes is the "hands-on" approach and it gives you a very direct way of manipulating inputs and inspecting outputs. This can be useful for exploration, prototyping and debugging.
reader = FARMReader(model="deepset/roberta-base-squad2")result = reader.predict( query="Which country is Canberra located in?", documents=documents, top_k=10)
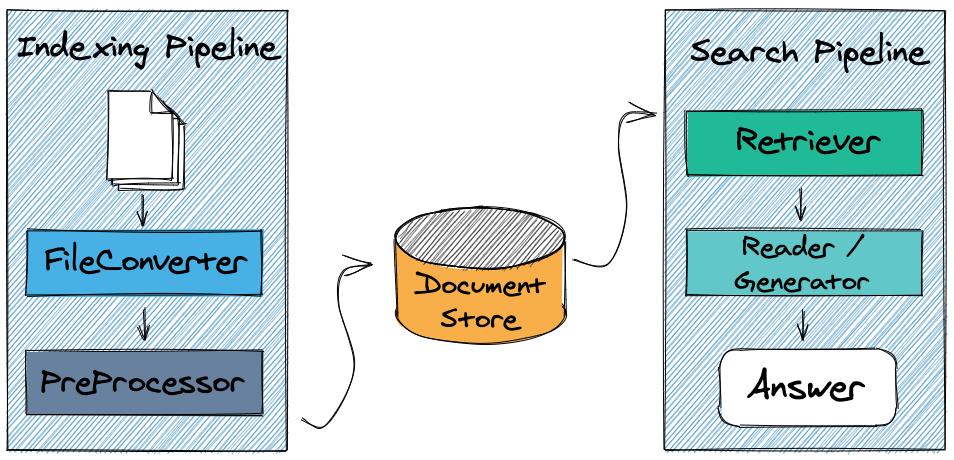
2) Pipelines
Haystack is built on the idea that great systems are more than the sum of their parts. By combining the NLP power of different Nodes, users can create powerful and customizable systems. The Pipeline is the key to making this modular approach work.
When adding Nodes to a Pipeline, the user can define how data flows through the system and which Nodes perform their processing step when. On top of simplifying data flow logic, this also allows for complex routing options such as those involving decision nodes.
p = Pipeline()p.add_node(component=retriever, name="Retriever", inputs=["Query"])p.add_node(component=reader, name="Reader", inputs=["Retriever"])result = p.run(query="What did Einstein work on?")
3) REST API
In order to deploy a search system, you will need more than just a Python script. Rather you need a service that can stay on, handle requests as they come in and also be callable by many different applications. For this, Haystack comes with a REST API that is designed to work in production environments.
When set up like this, you can load Pipelines from YAML files, interact with Pipelines via HTTP requests and connect Haystack to a user-facing GUIs.
curl -X 'POST' \ 'http://127.0.0.1:8000/query' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "query": "Who is the father of Arya Stark?", "params": {}}'
Why Use Pipelines for Search?
The value of chaining together different Nodes is clearest when looking at the Retriever-Reader Pipeline. It is one of the most common systems built in Haystack and it harnesses the reading comprehension power of the Reader but also applies it to large document bases with the help of the Retriever.
Readers, also known as Closed-Domain Question Answering systems in Machine Learning speak, are powerful models that do close analysis of documents and perform the core task of question answering. The Readers in Haystack are trained from the latest transformer based language models and can be significantly sped up using GPU acceleration. However, it is not currently feasible to use the Reader directly on large collection of documents.
The Retriever assists the Reader by acting as a lightweight filter that reduces the number of documents that the Reader has to process. It does this by scanning through all documents in the database and quickly identifying the relevant and dismissing the irrelevant. In the end, only a small set of candidate documents are passed on to the Reader.
p = ExtractiveQAPipeline(reader, retriever)result = p.run(query="What is the capital of Australia?")
Using just a Retriever will not enable users to perform question answering. And using just a Reader would be unacceptably slow. The power of this system comes from the combination of the two.
Question Answering Tutorial: To start building your first question answering system, see our Introductory Tutorial
The Retriever-Reader pipeline is by no means the only one that Haystack offers, but it is perhaps the most instructive for showing the gains from combining Nodes. Many of the synergistic Node combinations are covered by our Ready Made Pipelines but we are sure there many still to be discovered!